

We’ve discussed a few times recently how deep learning systems are sometimes inscrutable. They work out how to do things for themselves, and there may be no way to tell what method they are using. I’ve suggested that it’s worse than that; they are likely to be using methods which, though sound, are in principle incomprehensible to human beings. These unknowable methods may well be a very valuable addition to our stock of tools, but without understanding them we can’t be sure they won’t fail; and the worrying thing about that is that unlike humans, who often make small or recoverable mistakes, these systems have a way of failing that is sudden, unforgiving, and catastrophic.
So I was interested to see this short interview with Been Kim, who works for Google Brain (is there a Google Eyes?) has the interesting job of building a system that can explain to humans what the neural networks are up to.
That ought to be impossible, you’d think. If you use the same deep learning techniques to generate the explainer, you won’t be able to understand how it works, and the same worries will recur on another level. The other approach is essentially the old-fashioned one of directly writing an algorithm to do the job; but to write an explicit algorithm to explain system X you surely need to understand system X to begin with?
I suspect there’s an interesting general problem here about the transmission of understanding. Perhaps data can be transferred, but understanding just has to happen, and sometimes, no matter how helpfully the relevant information is transmitted, understanding just fails to occur (I feel teachers may empathise with this).
Suppose the explainer is in place; how do we know that its explanations are correct? We can see over time whether it successfully picks out systems that work reliably and those that are going to fail, but that is only ever going to be a provisional answer. The risk of sudden unexpected failure remains. For real certainty, the only way is for us to validate it by understanding it, and that is off the table.
So is Been Kim wasting her time on a quixotic project – perhaps one that Google has cynically created to reassure the public and politicians while knowing the goal is unattainable? No; her goal is actually a more modest, negative one. Her interpreter is not meant to provide an assurance that a given system is definitely reliable; rather, it is supposed to pick out one’s that are definitely dodgy; and this is much more practical. After all, we may not always understand how a given system executes a particular complex task, but we do know in general how neural networks and deep learning work. We know that the output decisions come from factors in the input data, and the interpreter ought to be able to tell us what factors are being taken into account. Then, using the unique human capacity to identify relevance, we may be able to spot some duds – cases where the system is using a variable that tracks the relevant stuff only unreliable, or where there was some unnoticed problem with the corpus of examples the system learnt from.
Is that OK? Well, in principle there’s the further risk that the system is actually cleverer than we realise; that it is using features (perhaps very complex ones) that actually work fine, but which we’re too dim to grasp. Our best reassurance here is again understanding; if we can see how things seem to be working, we have to be very unlucky to hit a system which is actually superior but just happens, in all the examined cases, to look like a dodgy one. We may not always understand the system, but if we understand something that’s going wrong, we’re probably on firm ground.
Of course, weeding out egregiously unreliable systems does not solve the basic problem of efficient but inscrutable systems. Without accusing Google of a cunning sleight of hand after all, I can well imagine that the legislators and bureaucrats who are gearing up to make rules about this issue might mistake interpreter systems like Kim’s for a solution, require them in all cases, and assume that the job is done and dusted…

 Machine learning and neurology; the perfect match?
Machine learning and neurology; the perfect match?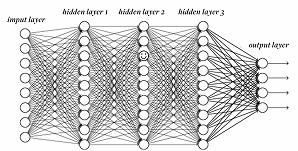 Interesting piece
Interesting piece