
 A treat for lovers of bizarre thought experiments, Rick Grush’s paper Some puzzles concerning relations between minds, brains, and bodies asks where the mind is, in a sequence of increasingly weird scenarios. Perhaps the simplest way into the subject is to list these scenarios, so here we go.
A treat for lovers of bizarre thought experiments, Rick Grush’s paper Some puzzles concerning relations between minds, brains, and bodies asks where the mind is, in a sequence of increasingly weird scenarios. Perhaps the simplest way into the subject is to list these scenarios, so here we go.
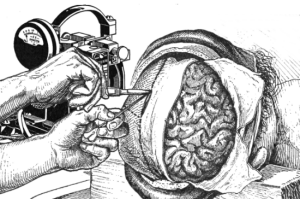
Airhead. This a version of that old favourite, brain-in-a-vat. Airhead’s brain has been removed from its skull, but every nerve ending is supplied with little radio connectors that ensure the neural signals to and from the brain continue. The brain is supplied with everything it needs, and to Airhead everything seems pretty normal.
Rip. A similar set-up, but this time the displacement is in time. Signals from body to brain are delayed, but signals in the opposite direction are sent back in time (!) by the same interval, so again everything works fine. Rip seems to be walking around three seconds, or why not, a thousand years hence.
Scatterbrain. This time the brain is split into many parts and the same handy little radio gizmos are used to connect everything back up. The parts of the brain are widely separated. Still Scatterbrain feels OK, but what does the thought ‘I am here’ even mean?
Raid. We have two clones, identical in every minutest detail; both brains are in vats and both are connected up to the same body – using an ‘AND’ gate, so the signal passes on only if both brains send the same one (though because they are completely identical, they always will anyway). Two people? One with a backup?
Janus. One brain, two bodies, connected up in the way we’re used to by now; the bodies inhabit scrupulously identical worlds: Earth and Twin Earth if you like.
Bourdin. This time we keep the identical bodies and brains, wire them up, and let both live in their identical worlds. But of course we’re not going to leave them alone, are we? (The violence towards the brain displayed in the stories told by philosophers of mind sometimes seems to betray an unconscious hatred of the organ that poses such intractable questions – not that Grush is any worse than his peers.) no; what we do is switch signals from time to time, so that the identical brains are linked up with first one, then the other, of the identical bodies.
Theseus. Now Grush tells us things are going to get a little weird… We start with the two brains and bodies, as for Bourdin, and we divide up the brains as for Scatterbrain. Now we can swap over not just whole brains, but parts and permutations. Does this create a new individual every time? If we put the original set of disconnected brain parts back together, does the first Theseus come back, or a fresh individual who is merely his hyper-identical twin?
Grush tests these situations against a range of views, from ‘brain-lubbers’ who believe the mind and the brain are the same thing, through functionalists of various kinds, to ‘contentualists’ who think mind is defined by broad content; I think Grush is inventing this group, but he says Dennett’s view of the self as ‘a centre of narrative gravity’ is a good example. It’s clearly this line of thinking he favours himself, but he admits that some of his thought experiments throw up real problems, and in the end he offers no final conclusion. I agree with him that a discussion can have value without being tied to the defence of a particular position; his exploration is quite well done and did suggest to me that my own views may not be quite as coherent as I had supposed.
He defends the implausibility of his scenarios on a couple of grounds. We need to test our ideas in extreme circumstances to make sure they are truly getting the fundamentals and setting aside any blinkers we may have on. Physical implausibilities may be metaphysically irrelevant (nobody believes I’m going to toss a coin and get tails 10,000 times in a row, but nobody sees a philosophical problem with talking about that case). To be really problematic, objections would have to raise nomological or logical impossibilities.
Well, yes but… All of the thought experiments rely on the idea that nerves work like wires, that you can patch the signal between them and all will be well. The fact that that instant patching of millions of nerves is not physically possible even in principle may not matter. But it might be that the causal relations have to be intact; Grush says he has merely extended some of them, but picking up the signal and the relaying it is a real intervention, as is shown when later thought experiments use various kinds of switching. It could be argued that just patching in radio transmitters destroys the integrity of the causality and turns the whole thing into a simulation from the off.
The other thing is, should we ask where the mind is at all? Might not the question just be a category mistake? There are various proxies for the mind that can be given locations, but the thing itself? Many years ago, on the way to nursery, my daughter told me a story about a leopard. What is the location of that story? You could say it is the streets where she told it; you could say it is in the non-existent forest where the leopard lived. You could say it is in my memory, and therefore maybe in my brain in some sense. But putting the metaphors aside, isn’t it plausible that location is a property these entities made of content just don’t have?
 Social problems of AI are raised in two government reports issued recently. The first is
Social problems of AI are raised in two government reports issued recently. The first is  We might not be able to turn off a rogue AI safely. At any rate, some knowledgeable people fear that might be the case, and the worry justifies
We might not be able to turn off a rogue AI safely. At any rate, some knowledgeable people fear that might be the case, and the worry justifies  The unconscious is not just un. It works quite differently. So says Tim Crane in a persuasive draft
The unconscious is not just un. It works quite differently. So says Tim Crane in a persuasive draft